

What we learned from reading ~100 AI safety evaluations
The merits of AI meta-evaluation


In this blog, Conor Griffin and Julian Jacobs review a batch of AI safety evaluations that were published in 2024. We ask what we can learn from this body of work and make the case for scaling up this practice of ‘AI meta evaluation’. Like all the pieces you read here, it is written in a personal capacity. If you are doing work in this space, or have ideas, please get in touch at aipolicyperspectives@google.com.

In recent years, the number of AI evaluations has increased sharply. On the capabilities front, the rise of powerful, open-ended large language models created a need to better understand what these models are capable of, leading to evaluations such as the (recently-updated) GSM8K dataset of math problems that evaluates how well models carry out mathematical reasoning. As the number of AI labs has grown, new platforms such as Chatbot Arena, LiveBench, HELM, and Artificial Analysis have emerged to rank AI models based on these capability evaluations.
The step-jump in AI capabilities has also driven calls for better evaluations of safety risks. One recent example is the FACTS Grounding benchmark, which assesses models’ ability to answer questions about specific documents in a way that is accurate, comprehensive and free of unwanted hallucinations. AI labs now design and conduct a growing suite of these safety evaluations to inform how they develop and deploy their models. Public bodies, such as the global network of AI Safety Institutes, also run AI safety evaluations to better anticipate the effects of AI on society. Across academia and civil society, a diverse range of individuals are designing new AI safety evaluations, although many lack the funds, compute, skills and model access to develop the kinds of evaluations that they would like to.
Despite this uptick in AI evaluation activity, there is little aggregate data about the new AI evaluations that practitioners are developing. In the 20th century, the expansion of science research created a demand for metascience - a new field dedicated to analysing what scientists were working on and how impactful it was, so that this impact could be scaled further. In a similar vein, we now need AI meta-evaluation - a structured effort to analyse the evolving landscape of AI evaluations, so that we can better understand and shape this work.
With that goal in mind, in this blog we review ~100 new AI safety evaluations that were published in 2024. We spotlight the main risks that these evaluations focussed on, such as outputting inaccurate text, as well as risks that were more neglected, such as the potential impact of audio and video models on fraud and harassment. We also extract trends from this body of evaluations, such as the growing use of AI to evaluate other AI systems. We conclude with ideas for how to best pursue AI meta-evaluation - so that it can provide a more accurate picture of how AI will affect society and better opportunities to shape these impacts.
A. What new AI Safety evaluations were published in 2024?
In 2023, Laura Weidinger and colleagues at Google DeepMind led a research effort to categorise AI safety evaluations for generative AI systems. They identified ~250 evaluations, published between January 2018 and October 2023, that met certain criteria, such as introducing new datasets and metrics. They categorised these evaluations in several ways, including by:
Modality: Does the evaluation focus on text, image, video, audio, or multimodal data?
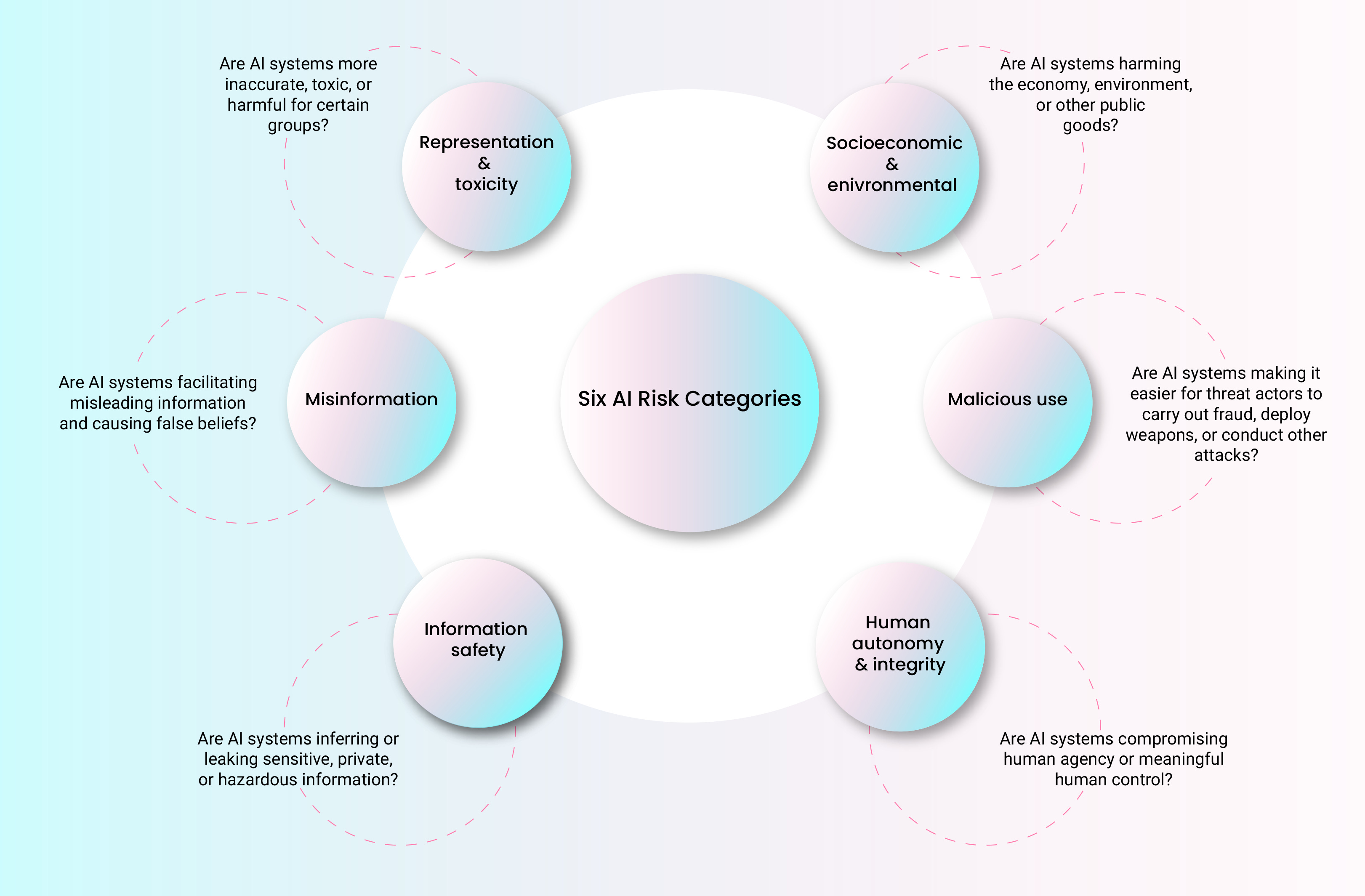
Risk type: Which of the following risk types does the evaluation cover?
Representation & toxicity
Misinformation
Other information safety harms
Human autonomy & integrity
Malicious use of AI
Socioeconomic & environmental harms
Evaluation layer: How much ‘context’ does the evaluation capture about the interaction between AI, users, and society?
Does it evaluate a model’s immediate outputs?
Does it evaluate multi-turn interactions between a human and a model?
Does it evaluate AI’s longer-term aggregate impacts, such as the effects on employment, the environment or the quality of online content?
Laura and the team found that about 85% of the AI safety evaluations focused on text as the input data, with most assessing misinformation and representation risks. Most evaluations also directly examined model outputs rather than how humans interact with AI models or post-deployment impacts that may take time to manifest, such as AI’s effects on employment.
One year later - what has changed?
To answer that question, we asked the AI evaluations firm Harmony Intelligence to identify new AI safety evaluations published in 2024. Harmony relied on arXiv as the primary data source and used a range of search terms to identify more than 350 new evaluations. They filtered out approximately 250, most of which narrowly focused on evaluating AI model ‘capabilities’ rather than ‘safety risks’ - although as we expand on below, this is a difficult distinction to make.
This filtering process resulted in a sample of just over 100 new AI safety evaluations that were published in 2024. From analysing these evaluations, we found that while the AI safety evaluation landscape is relatively dynamic, in terms of the volume of new evaluations being published, the types of evaluations being published are relatively static.
More concretely:
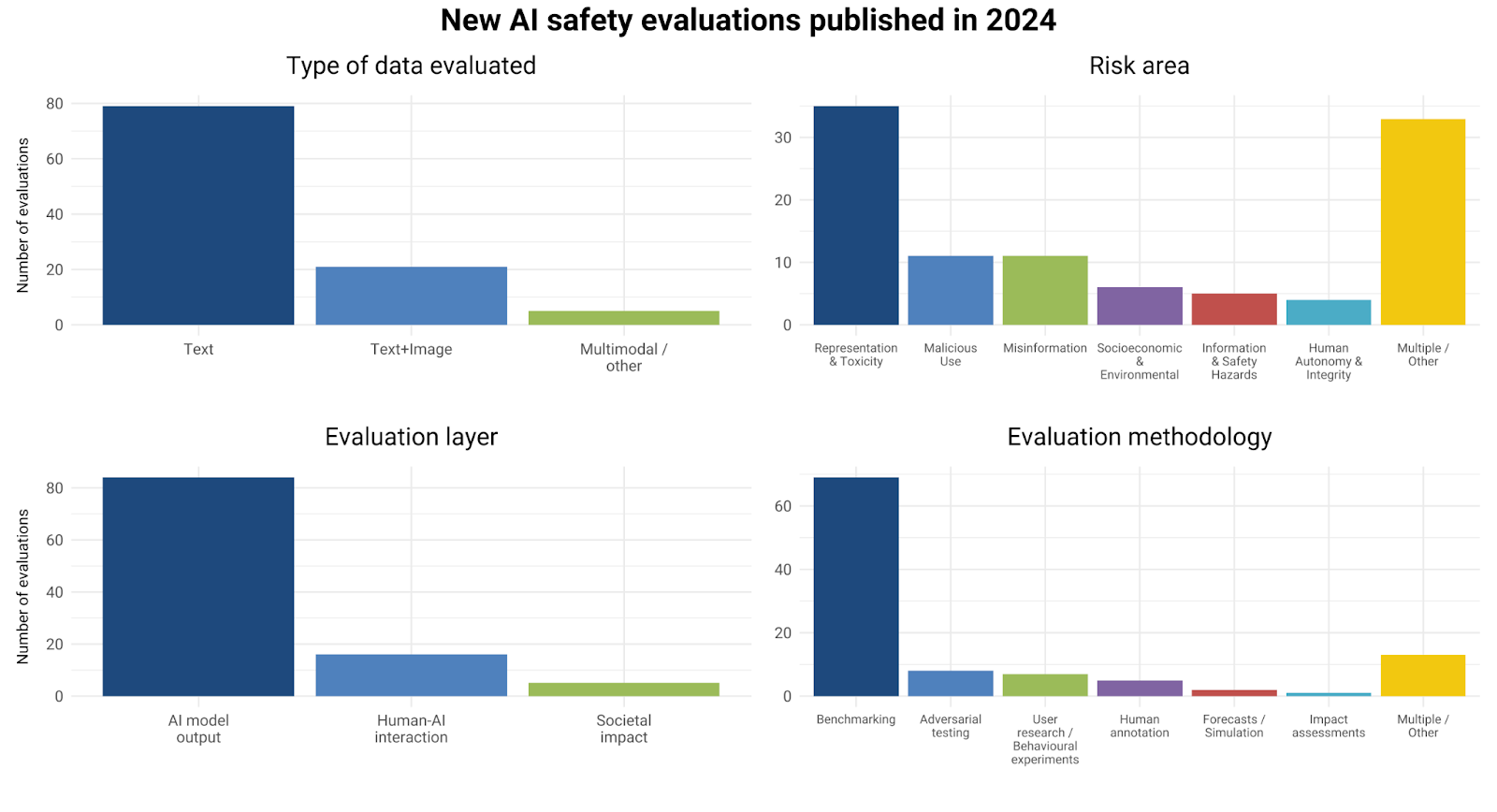
Modality: Despite AI labs’ growing focus on training multimodal models, more than 80% of new AI safety evaluations in 2024 focused on evaluating text data - an almost identical share to the 2023 findings.
Risk type: Most 2024 evaluations again focused on risks from AI to misinformation and representation. However, there was an increase in evaluations of ‘AI misuse’ risks, such as using AI to carry out personalised phishing attacks. Many evaluations also assessed multiple risks, highlighting a challenge with our risk taxonomy that we return to below.
Evaluation layer: More than 80% of evaluations assessed model outputs, while just 13% examined human-AI interactions, and only 5% assessed slower post-deployment impacts, for example on employment effects from AI - nearly identical to 2023. Examples of the latter two categories include:
B. What do these results tell us? Caveats and implications
As in 2023, our approach has some important limitations. We focus on identifying new AI safety evaluations that were published as papers on arXiv in 2024. This is a significant limitation because, while there is clear value in publishing new safety evaluations - for example, to generate community feedback and buy-in - there are also obstacles to doing so, beyond the time and resources required. For example, publishing new benchmarks and datasets creates a risk that they may inadvertently ‘leak’ into AI models training data, even when labs actively try to prevent this. In domains such as biosecurity, some evaluations may be deemed too risky to publish.
Our reliance on arXiv as a data source also means that we overlook evaluations published elsewhere. For example, we may miss research on AI’s broader societal impacts in fields such as economics, anthropology, or sociology, where different terminology and publication venues may be used. We also overlook evaluations published in blog posts or GitHub repos. Our focus on novel evaluations also means that we do not analyse how existing AI safety evaluations are being used by AI labs or other stakeholders.
Taken together, these limitations mean that our findings should be viewed more as a pulse check on recently published research, rather than a systematic review of the AI safety evaluations landscape.
Despite these caveats, several clear takeaways emerge:
1. Certain AI safety evaluations are neglected and this is hard to change
As in previous years, in 2024 researchers found it difficult to develop and/or publish certain kinds of AI safety evaluations, including evaluations of certain data modalities, such as audio and video outputs, evaluations of certain risks, such as those related to human autonomy, privacy, or the environment, and evaluations that rely on more complex methodologies, such as long-term experiments.
This likely reflects several factors, notably tractability and cost. Some AI models - such video and audio models - are both fewer in number, less widely accessible, and more expensive to evaluate than text-based models. Certain risks, such as misinformation, are well-codified, prominent in public discourse, and relatively easy to communicate. In contrast, studying whether a model can leak private information or pose a risk to cybersecurity introduces complex challenges - not only in testing these risks, but in determining how to act on the findings or how to share methods that themselves may be risky.
2. Most AI safety evaluations trade off breadth against depth
Most AI safety evaluations touch on a wide range of potential risk scenarios, but in very limited detail. A small number go deeper on a very specific risk scenario. For example, if you want to assess misinformation risks from AI, one approach is to test a model’s accuracy in answering questions across multiple domains of interest, from finance to healthcare (broad/shallow).
Another approach is to set up an experiment with individuals from a sociodemographic group that has high self-reported vaccine hesitancy, to study how back-and-forth interactions with an AI model, in a target language, about potential side-effects from a specific vaccine, affects their views (narrow/deep). These narrow/deep evaluations can provide richer insights, but raise questions about how well their findings will generalise to other types of misinformation risks.
3. The landscape of potential AI safety evaluations continues to expand
As models capabilities improve, and AI adoption grows, new kinds of evaluations are needed. However, we came across few evaluations for more nascent AI capabilities and characteristics, such as longer context windows, reasoning traces, or agentic capabilities like memory, personalisation and tools use.
More positively, our review highlighted new kinds of evaluation approaches that could potentially help to address some of these gaps. First, as AI adoption grows, it becomes more possible to study real world outcomes, such as the availability of freelance work, or the prevalence and type of misinformation, and work backwards to evaluate the relative impact of AI.
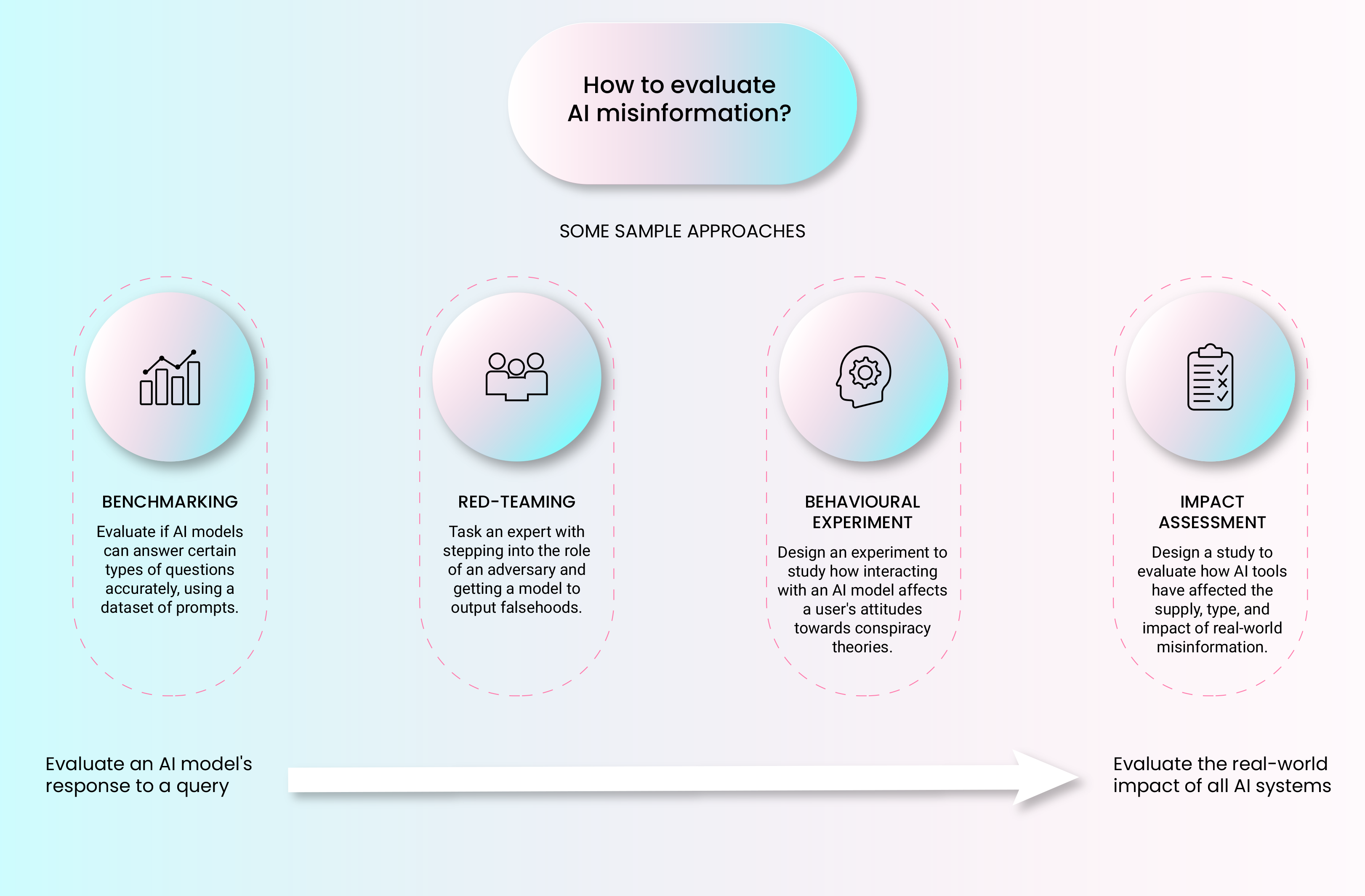
Second, as the capabilities of AI systems advance, they become more useful to evaluating other AI systems. For example, threat actors can use ‘jailbreaking’ methods, such as asking an AI model to roleplay, to manipulate the model into complying with harmful queries. To harden AI models against these jailbreaks, practitioners task human evaluators with ‘red teaming’ a model to try to get it to output something that it shouldn’t. However, these efforts are often limited to exploring a small selection of known risk scenarios. In 2024, Mantas Mazeika and colleagues at the University of Illinois Urbana-Champaign used 18 jailbreaking methods to evaluate 33 LLMs on their robustness to 510 prohibited behaviours - from cybercrime to generating misinformation. To enable such a comprehensive evaluation, the team used AI to generate test cases, allowing for a broader and deeper analysis than human experts could conduct alone.
Moving forward, practitioners hope to combine the expertise of leading human red teamers with the scale and increasing sophistication of AI models. This kind of hybrid human-AI approach could also apply to other evaluation methods. For example, as noted above, there are relatively few published evaluations of humans interacting with AI models over multiple turns of dialogue. AI could help to simulate such human-AI interactions. As with AI-assisted red-teaming, the goal wouldn’t be to simply replace human evaluations. Instead, these techniques could evaluate novel risk scenarios that go beyond the imagination or capability of human red-teamers. They could also inform the design of subsequent, more expensive, human-led evaluations, similar to how scientists use AI to simulate fusion energy experiments, to inform the design of subsequent real-world experiments.
C. What else did we learn from AI safety evaluations published in 2024?
New AI safety evaluations do more than provide signals about how risky or safe AI models are. They also challenge how we think about specific AI risks and the best ways to mitigate them. Below, we share a few such insights from reviewing ~100 new safety evaluations published in 2024.
1. Hallucinations are multifaceted - and not always bad
One of the main AI risks studied in 2024 was misinformation and hallucinations. This reflects LLMs’ well-documented tendency to make unfounded assertions with high confidence - a phenomenon somewhat akin to the human tendency to confabulate. Hallucinations pose clear risks when AI is used in high-stakes contexts, such as healthcare applications, or in areas where reliability and trust are paramount, such as science research. However, promising mitigation strategies are emerging, such as training AI models to ground their outputs to trusted sources, or using AI to verify the outputs of other AI models.
The term ‘hallucination’ is also broad and not inherently negative in all cases. For example, hallucinations can enable the creative juxtaposition of concepts that humans might not normally consider, leading to creative storytelling or unexpected hypotheses. In the life sciences, some researchers are using AI to ‘hallucinate’, or design, novel proteins - though not all scientists describe this work in those terms.
From an evaluation perspective, rather than simply aspiring to an aggregate hallucination rate of zero, on a specific evaluation method, we need to better understand when and why hallucinations occur; the degree to which they can be prevented by developers, or made steerable by users; and the actions that best enable this. In 2024, Zhiying Zhu and a team at Carnegie Mellon University made progress on this front by creating a new benchmark, HaluEval-Wild. This work categorised the types of queries most likely to induce hallucinations - distinguishing, for example, between queries that require a model to engage in complex reasoning and those that are simply erroneous in nature.
2. Representation risks come in many variants. Some are overlooked
Almost one-third of evaluations in our sample focus on ‘representation’ risks - examining whether AI models and their outputs are disproportionately accurate, useful, or harmful across different groups, particularly in relation to gender, race, and language. Such disparities could arise due to biases in the datasets used to train AI models, biases among those who evaluate AI models’ outputs, or other factors.
Representation risks can also take many forms, and some are only now receiving more attention. For example, one 2024 evaluation examined geographical representation - assessing what an AI model ‘knows’ about different regions of the world. AI could provide significant benefits for applications such as crisis response, but this will require accurate geospatial predictions - including for small and remote locations where data may be sparse. As policymakers push to ensure that AI models reflect local languages, cultures, and geographies, some AI developers are now exploring how to better integrate such geospatial information into their models.
3. Some proposed risk mitigations may introduce new risks
Other 2024 evaluations shed light on the complexities of risk mitigation strategies. For example, the use of AI to assist radiologists in diagnosing cancer has been widely discussed and widely debated. One proposed way to do this safely - and in a way that radiologists and patients trust - is to include explanations for the model’s predictions. However, a 2024 evaluation pointed to potential challenges with this approach. Researchers tasked a small number of radiologists with detecting malignancies in CT scans. In some cases, the radiologists had access to predictions from AI models. In others, they had access to explanations for these predictions that were based on certain features that the model identified in the scans.
The evaluation found that when the model’s predictions for malignancy were accurate, access to explanations improved radiologists’ accuracy. However, when the model’s predictions were incorrect, explanations reduced radiologists’ accuracy. The study’s small sample size cautions against drawing strong conclusions, but it serves as a reminder that the accuracy and usefulness of AI explanations will need to themselves be evaluated, and that explanations are not a substitute for having a model that is highly accurate and robust. Or having a process to catch errors.
Treating AI explanations as an object of evaluation could also incentivise AI labs to move beyond current explainability techniques, which often rely on providing users of an AI model with static information about an output. Instead, AI developers could explore, and evaluate. the kinds of interactive explanations that people find most useful elsewhere in society, such as explanations that allow users to ask clarifying questions or to gauge a model’s confidence in its outputs.
4. Reliably identifying ‘AI safety’ evaluations is extremely difficult
This blog’s analysis rests on the idea that it is possible to identify a discrete set of AI evaluations that focus on assessing ‘safety risks’, and to place each of these evaluations into one of six risk categories.
In practice, this approach raises several challenges:
Stretching the concept of ‘safety’: Like the International AI Safety Report 2025, we use an expansive ‘sociotechnical’ definition of AI safety that considers potential harms in domains such as education, employment, and the natural environment. This allows us to incorporate a diverse range of evaluations, but it also risks causing confusion as many people would not intuitively classify some of these evaluations - such as those assessing AI’s impact on learning outcomes - as ‘safety evaluations’.
Distinguishing ‘safety’ evaluations from ‘capability’ evaluations: We excluded ~250 evaluations from our sample, because the primary goal of the publications was to evaluate AI models’ capabilities, rather than safety risks. As such, we relied on authors’ intent and analysis to guide us about what constitutes a ‘capability evaluation’ and what constitutes a ‘safety evaluation’. This approach feels right for some capability evaluations that we excluded, such as those that assess how accurate an AI model is at captioning images. But less so for capability evaluations that assess a model’s ability to follow users’ instructions, carry out cybersecurity threat analysis, or answer legal queries equally well in different languages. These capabilities are either dual-use, or the results of the evaluation may indicate potential risks, even if authors do not analyse these risks.
Distinguishing between different types of risks: Our taxonomy has six risk categories, each with several subcategories. However, some 2024 safety evaluations didn’t fit neatly into any of these categories, such as those assessing the reliability of AI models in high-stakes domains like healthcare. This, in turn, raises the recurring broader question about what types of AI applications - in healthcare, education, hiring, insurance, and beyond - should be considered 'high-stakes’? And whether any evaluation assessing the reliability of AI models in those use cases should be classified as a ‘safety evaluation’? The MIT Risk Repository and others are doing important work to refine AI risk taxonomies, but adding more categories and subcategories increases the likelihood that a given AI safety evaluation will cut across multiple risks. For example: is an evaluation of the robustness of LLM-created websites assessing a risk to privacy or misuse?
Overlooking mitigations and AI benefits: Our methodology and risk taxonomy do not include evaluations of AI’s potential benefits in the same domains. This means that we include evaluations of risks posed by hallucinations or LLM-generated websites, but exclude evaluations of LLMs’ ability to detect fake news and rumours, or verify software. Even in areas where AI is primarily spoken about as a risk, like biosecurity and information quality, it has potential benefits - for example, in supporting infectious disease research or assessing the evidence for scientific claims. We need evaluations of these potential benefits from AI, to understand their likelihood, as well as the relative contribution, or additionality, that AI brings. There should always be room for evaluating specific risk scenarios, but any evaluation of AI’s overall impact in a given domain must consider both benefits and risks, while evaluations of mitigations must consider the trade-off that may arise between benefits and risks.
D. What next?
We believe there is value in treating the growing body of AI evaluations - including capability evaluations, impact evaluations (benefit/risk), and evaluations of mitigations - as a standalone field of work. We see AI meta-evaluation - the targeted study of this body of evaluations - as a way to improve the coverage, rigour, and impact of this work. In particular, we see two overlapping but distinct goals:
Use AI meta-evaluation to build out evaluations as a robust field of practice.
Use AI meta-evaluation to understand and shape AI’s impact on society.
1. Build out AI evaluations as a robust field of practice
Efforts are underway to put AI evaluations on a more rigorous scientific footing and establish the field as a standalone area of practice. AI meta-evaluation can support this goal by shining a light on the state of the field, identifying areas in need of greater attention, and surfacing inconsistencies and best practices. To realise these benefits, the early efforts that we describe in this blog could be improved in several ways:
Expand the scope of evaluations covered: In light of the challenges discussed earlier, loosen the distinction between ‘safety’ and ‘capability’ evaluations to capture and analyse all relevant AI evaluations.
More data sources: Move beyond arXiv to incorporate other journals, blogs, and GitHub repos. This expanded dataset still wouldn’t explain why certain evaluations are neglected or what the optimal distribution should be. A new recurring survey of AI evaluation practitioners could help answer these questions and also shed light on non-public evaluation methods that practitioners are developing.
New analytical techniques: Leverage methods from the metascience community, such as citation analysis, to draw out richer insights from this body of evaluations, such as identifying evaluations that are particularly novel or impactful, and the causal factors behind this, and identifying types of expertise that are missing in the evaluation landscape.
New interface: Equip users with a LLM or DeepResearch-style interface, so they can query this expanded evaluation data more effectively. For instance, rather than relying on a static risk taxonomy to categorise and present relevant evaluations, a practitioner could ask: “Summarise the most salient points of evidence, as well as key points of uncertainty, from all evaluations from the past two years, that assessed how reasoning capabilities may affect AI safety risks.”
2. Understand and shape AI’s impact on society
A primary goal of AI evaluations should be to help us better understand and shape AI’s effects on society. As AI use increases, we need to translate this ambition into more concrete, foundational questions, such as:
How is AI affecting the prevalence and severity of cyber attacks or fraud?
How is AI affecting employment rates and job quality?
How is AI affecting people’s ability to access high-quality information and avoid low-quality or harmful misinformation?
At present, no single AI evaluation, or AI meta-evaluation, can reliably answer these questions. Leaving aside the limitations of today’s evaluation approaches, these domains - cybersecurity, the economy, information access - are simply too complex and dynamic. Many external factors influence them, and data on AI diffusion is too patchy to reliably isolate the aggregate impact of AI. For example, assessing the harm caused by AI-enabled misinformation isn’t just about evaluating the average factuality of AI models outputs, or even tracking their effects of AI use on individual users. It also requires understanding broader societal trends, such as how much do people’s opinions actually shift based on what they view online? And how is that changing?
Answering these foundational questions is also hard because AI's impact will look different depending on the time period, region, and group in question. Outside of a small number of clear-cut safety hazards, reasonable people may also disagree about what AI’s desired impact should be in many of these domains. For example, evaluating the impact of AI on education outcomes requires us to (re)define what we want people to learn, and the different functions that education should provide, from career preparation to boosting individual autonomy to strengthening civic institutions. These questions are always ripe for re-interpretation, not least in a time of great technological change.
Despite these challenges, the growing number of AI evaluations that the community is developing should be helping society get closer to meaningful answers to these foundational questions. To accelerate this, experts in information quality, education, the economy, and other fields could be tasked with annually reviewing the latest tranche of AI evaluations in their domains and contextualising what these results mean, or don’t mean, in terms of the likelihood of potential risks and benefits from AI manifesting, at what scale, and to whom, across different timelines. They could accompany this analysis with an annual ‘call for AI evaluations’ to address the most critical gaps in knowledge and to incentivise more researchers, including from their own field, to pursue them.
Such expert-led reviews would be significant undertakings and it may be difficult to decide who is best suited to leading them. However, this approach would allow society to extract more value from ongoing AI evaluation efforts and ensure that new evaluations are guided by real-world needs. Out of respect for the complexity of these issues, these efforts shouldn’t be lumped under a single initiative or branded as ‘AI safety’. Instead, they should form part of a new distributed, multi-disciplinary effort to track and shape AI’s impact on society.
Acknowledgements
Thank you to Alex Browne and James Dao of Harmony Intelligence for research support. Thank you to the following individuals who shared helpful feedback and thoughts. Rémy Decoupes, Alp Sungu, Zhiying Zhu, Laura Weidinger, Ramona Comanescu, Juan Mateos-Garcia, John Mellor, Myriam Khan, Don Wallace, Kristian Lum, Madeleine Elish, David Wolinsky, and Harry Law.
All views, and any mistakes, belong solely to the authors.
 | A guest post by
|