



As the world panicked over the Financial Crisis in 2008, aghast at the risks incurred by bankers and investors, a few academics stepped forth, offering both an explanation (Rational people act irrationally!) and a proposition (Nudge them to wiser decisions!). In haste and hope, behavioural science blossomed, with governments establishing “nudge units,” consultancies flinging around the word “behavioural,” and self-help books accumulating on bedside tables.
But in recent years, the most-potent force for behavioural change has been technology, while behavioural science—though enjoying notable successes—has not always fulfilled the early hopes. Could artificial intelligence change that, supplying the superlative platform for behavioural interventions? And might behavioural findings help developers build better AI?
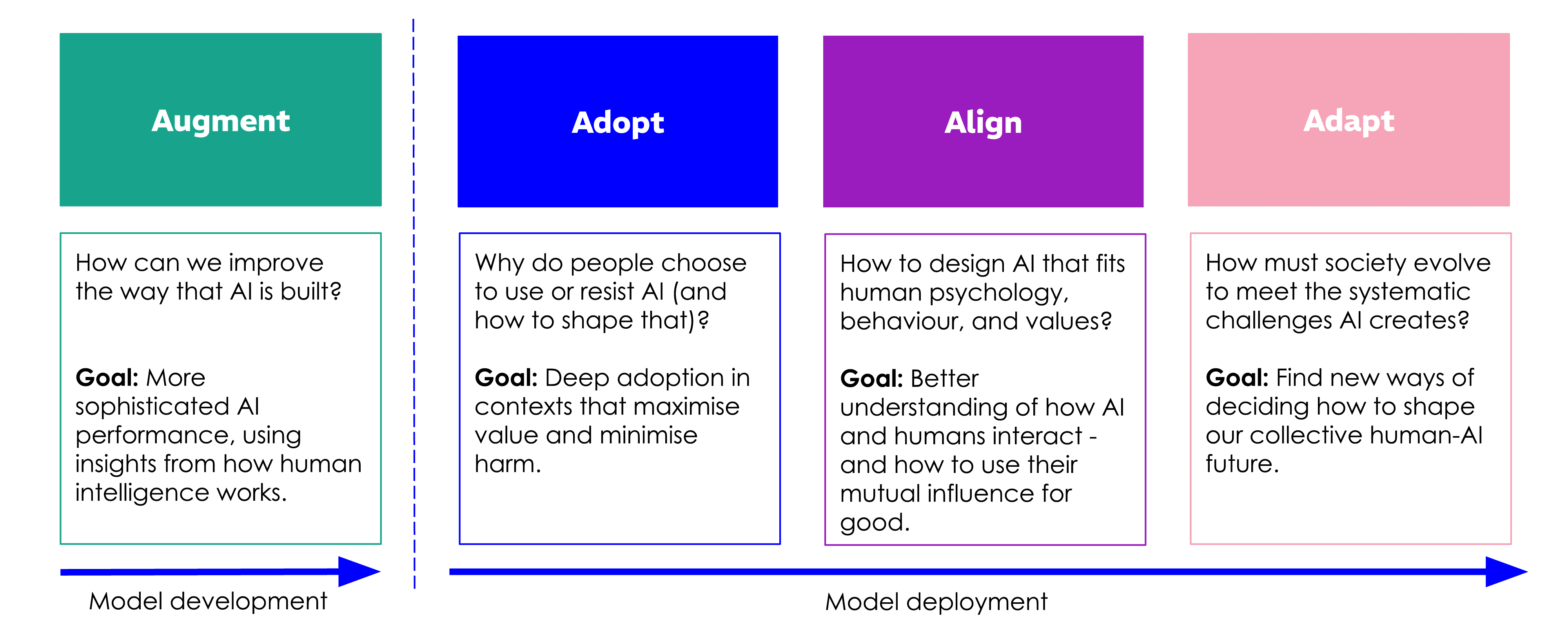
To seek answers, AI Policy Perspectives visited the original “Nudge Unit” (founded in 2010 by the UK government, then spun into a private company, the Behavioural Insights Team, or BIT), to quiz the authors of a new paper, AI & Human Behaviour, which presents four ways for the science to improve the tech: “Augment” (behavioural findings for better AI), “Adopt” (get people to engage with AI), “Align” (help AI fit human values), and “Adapt” (guide society in dealing with AI impacts).
—Tom Rachman, AI Policy Perspectives
[Interview edited and condensed]
WHERE IS BEHAVIOURAL SCIENCE IN THE AGE OF AI?
Tom Rachman: After the bestseller Nudge came out in 2008, there was huge optimism about behavioural science as an inexpensive route to wiser policy. What is the state of applied behavioural science today?
Elisabeth Costa (BIT chief of innovation and partnerships): If you think back to early projects that really proved the concept of behavioural science, there were relatively straightforward behaviours and questions like, “How do you get people to pay their tax on time?”—so, simple interventions that were shown to be incredibly effective, and cost effective, and able to be rolled out at scale. All of those things are still happening across national governments and other organizations, and are still very much worth doing. But it has become more business-as-usual. So, what we’ve been doing at BIT is thinking less about just intervening at a certain point, and thinking how to shift more complex behaviours that are systemic—things like corruption, violence against women and girls, and the societal impacts of AI.
Tom: From one perspective, AI changing behaviour could be beneficial. From another perspective, it’s frightening. Do the institutions of applied behavioural science—your organization, behavioural scientists in government, those in the business world—have a vision of how to best employ AI?
Elisabeth: Behavioural institutions are still sorting out their house views on this. For us, we have seen promise from how we use AI in our own behavioural-science projects, and therefore how we can have greater impact at scale. We do recognize the societal risks and risks of misalignment, but also keep an eye on the potential upside and benefits to society and individuals. For example, we ran an experiment looking at whether LLMs can de-bias our decisions, with promising results. So we think there’s cause for optimism.
Tom: We’ll come back to that study. First, could you talk about behavioural research, and how AI can be employed there?
Elisabeth: We’re using it for things like speeding up and improving literature reviews. We’re using it to dramatically scale qualitative research, too—for example, using AI interviewers. We’re also at the very early stages of experimenting with synthetic participants. And we’re thinking about how to build more precise interventions that target particular behavioural barriers, or particular biases and contexts. Deploying AI across the whole life cycle of a social-science research project, you should be able to do more, get a much richer understanding, and have a much greater impact.
SETTING A HUMANE PATH
Tom: One of the contentions in your paper AI & Human Behaviour is that the development of artificial intelligence is overlooking our behaviour, and that there is a narrowing window in which to act. Could you explain that?
Elisabeth: What we’ve seen in previous technology adoption is that norms and behaviours harden quickly, and early experimentation tends to lead to organizational path dependency. It’s hard to say exactly where AI is on that spectrum. But we’re all sitting here with laptops with QWERTY keyboards. The QWERTY keyboard was invented in the 1800s, and it’s demonstrably not the best design for a keyboard, ergonomically or in terms of typing speed. There’s reason to think the evolution of AI will have similar path dependencies, which means that this governance question is really important: How do we decide what we definitely do, and don’t, want AI to be used for?
Tom: What are you concerned about becoming fixed?
Elisabeth: In an organizational context, which tasks or roles become automated versus augmented by AI—those are decisions that will probably be quite sticky and quite hard to unravel. Similarly in our personal lives, the extent to which we rely on it for different tasks affects the extent to which our cognition is still sharp and active, or if we’re falling into traps of cognitive degrading and offloading.
Tom: One of the things you suggest is post-training to help AI systems align with users’ long-term wellbeing. What kind of progress is being made on translating the concept of wellbeing into a stable and meaningful metric that reward models could optimize for?
Michael Hallsworth (BIT chief behavioural scientist): We make the point that current training methods, like reinforcement learning from human feedback, RLHF, are too simple. They’re good at training an AI to give an answer a human likes in the moment, but that can increase sycophancy, and perhaps even increase “present bias,” where the AI pushes what feels gratifying now, rather than what pays off in the long run. So, rather than just optimizing for what’s “liked,” we need to find ways to reward responses that support long-term psychological well-being, meaning concepts like meaning, growth, and mastery. This could mean giving high scores to an AI response that introduces “helpful friction” or challenges a user’s assumptions. Frankly, progress is pretty slow—it’s hard to translate these concepts into precise objectives that a reward model can actually optimize for! There’s a lot that behavioural scientists and computer scientists can do together here.
COULD AI NUDGES UNDERMINE US?

Tom: If these systems were somehow “nudging” people to long-term well being, what effect would this have on people’s sense of autonomy and competence?
Michael: If done the wrong way, it could undermine feelings of autonomy, sure. We highlight that risk. But the current situation is also creating risks in terms of overconfidence and bias reinforcement. We’re pushing for an approach that encourages reflection rather than suppressing it—we call it “collaborative metacognition.” For example, if your stated goal is long-term saving but your queries are drifting toward risky day-trading, you might get a prompt saying, “I’ve noticed the strategies we’re discussing have moved toward higher risk than your original goal … Is this a deliberate change in your strategy, or would it be helpful to revisit your initial goals?”
Tom: Your paper raises the idea of AI systems that are emotionally proactive, intervening according to the user’s mood: “It can learn to be more reassuring to a stressed user or to guide a user away from a cognitive bias.” Does this assume that people should never be in aversive states?
Elisabeth: No, I don’t think so. Because expressions of anger and frustration can be useful and constructive. The ideas around aligning AI to match human psychology, particularly around mood adaptation, are early-stage and speculative. But you don’t want a flat emotional state; that’s not human. Equally, there are times when we want to moderate our emotions, and AI could help us do that, particularly in difficult interpersonal interactions.
Tom: So, if we have AI systems that allow certain aversive feelings, how would they decide which are okay? Your paper cites the notion of the system “reading the room.” But different humans read rooms differently.
Elisabeth: Alignment comes with the biggest questions. We propose deliberative mechanisms to help societies decide together where they do, and don’t, want AI to intervene. But we are at an extremely early stage of understanding how AI influences us, and therefore what is the right level of alignment to be aiming for.
Tom: What should AI developers be doing about this right now?
Michael: A few different things. First, they need to “measure what matters.” That means going beyond simple task-completion metrics to assessing the psychological impact of the AI model—how is it shifting user confidence, decision-making, or sentiment over time? Second, they need to practice “influence transparency.” That’s especially crucial where an AI is designed to be persuasive, like in sales or support bots. Developers should be testing the effects of transparency. That could include things like flagging when an AI is using a specific persuasive technique or even just expressing a simulated emotion. Third, they should be “red-teaming for persuasion.” This goes beyond typical red-teaming. It means actively testing how their systems could be used to manipulate users, engineer dependence, or create “preference drift,” where goals and opinions mutate through AI interaction without the user realizing. Finally, they should use “behavioural briefings” to help the AI “read the room.” Those briefings are an inference-time adaptation that helps a model detect when a user is likely stressed or falling prey to a common bias, and adapt its strategy accordingly.
AI VS. COGNITIVE BIAS
Tom: You mentioned a recent experiment looking at how AI could help manage cognitive biases. What did you learn?
Deelan Maru (BIT senior policy advisor): We ran a study with about 4,000 adults in the US and the UK. We randomized them into a control group; a group that had an LLM that they could interact with, if they chose to; a group that had an LLM that they must use; and a fourth group that had to use a reflective LLM, which just asked questions to help the individual understand their choices, but wouldn’t give direct answers. We took the participants through a series of common behavioural-bias scenarios, involving the sunk-cost fallacy, outcome bias, anchoring effects, and the decoy effect. Finally, we took away the LLM entirely from all groups, and asked them questions again on common behavioural biases, to test whether the de-biasing persisted. In three of the four behavioural biases—the sunk-cost fallacy, outcome bias, and anchoring effects—the “mandated use” LLM was successful. Only with the decoy effect, it didn’t have a de-biasing effect. However, we also saw some evidence that these debiasing effects were only temporary.
Tom: Did your findings suggest any design ideas for AI?
Deelan: We thought about web browsers, where you could have AI pop-ups that appear and tell you, “Here you’re seeing something which has a sunk-cost effect—consider choosing X instead.” It could be something that you subscribe to that operates across the browser, rather than you having to go into an LLM each time and ask.
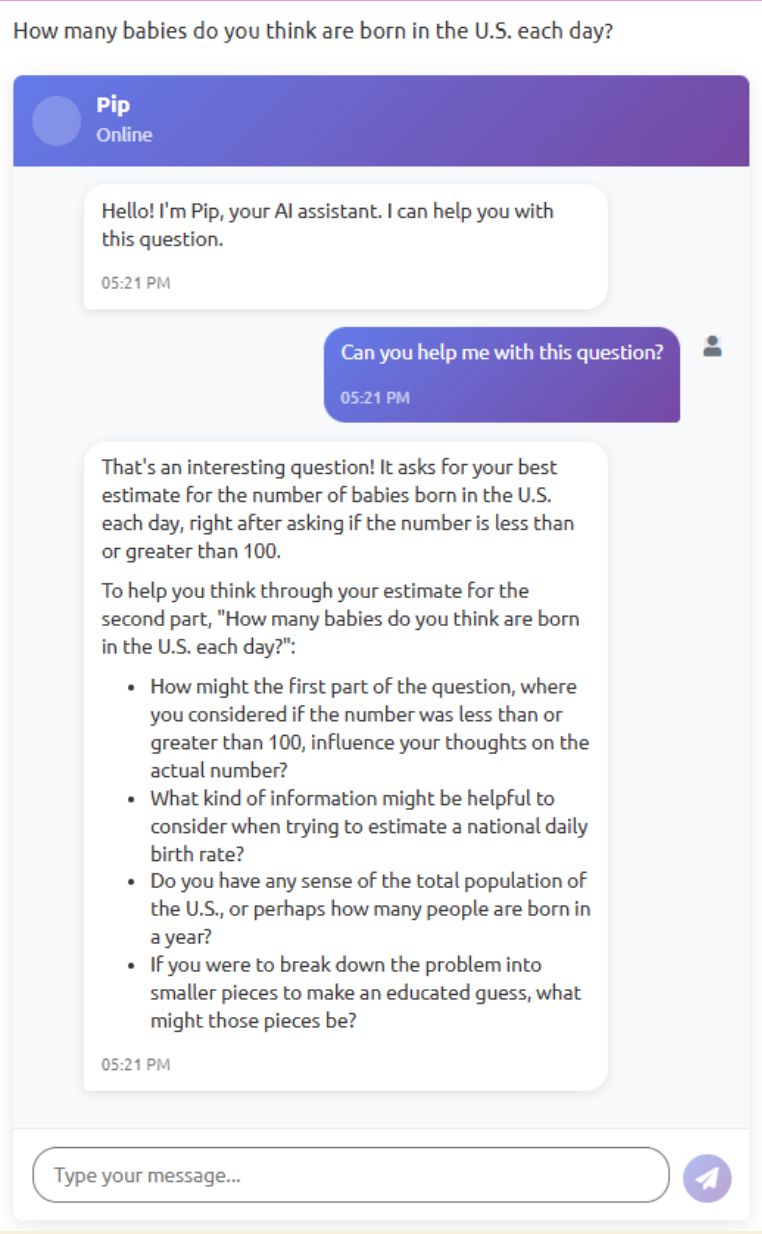
Elisabeth: With the “reflective LLM” group in the experiment, we saw mixed effects, but still think there could be merit there. In the anchoring example, we asked people how many babies were born in the US every day, and gave people either a low anchor of 100 or a high anchor of 50,000. The reflective LLM tried to lead people through questions like, “Okay, what’s the overall population? … What’s the birth rate? … Therefore, how many babies would you expect to be born every day? … Are either of these estimates wildly off?” You’d need to balance this with ease of use. But there are cases where you could have quick metacognitive prompts to lead you to a better answer.
AI THINKING, FAST AND SLOW
Tom: Does behavioural research offer ideas for how to develop AI? I believe you’ve advocated a “neurosymbolic” approach.
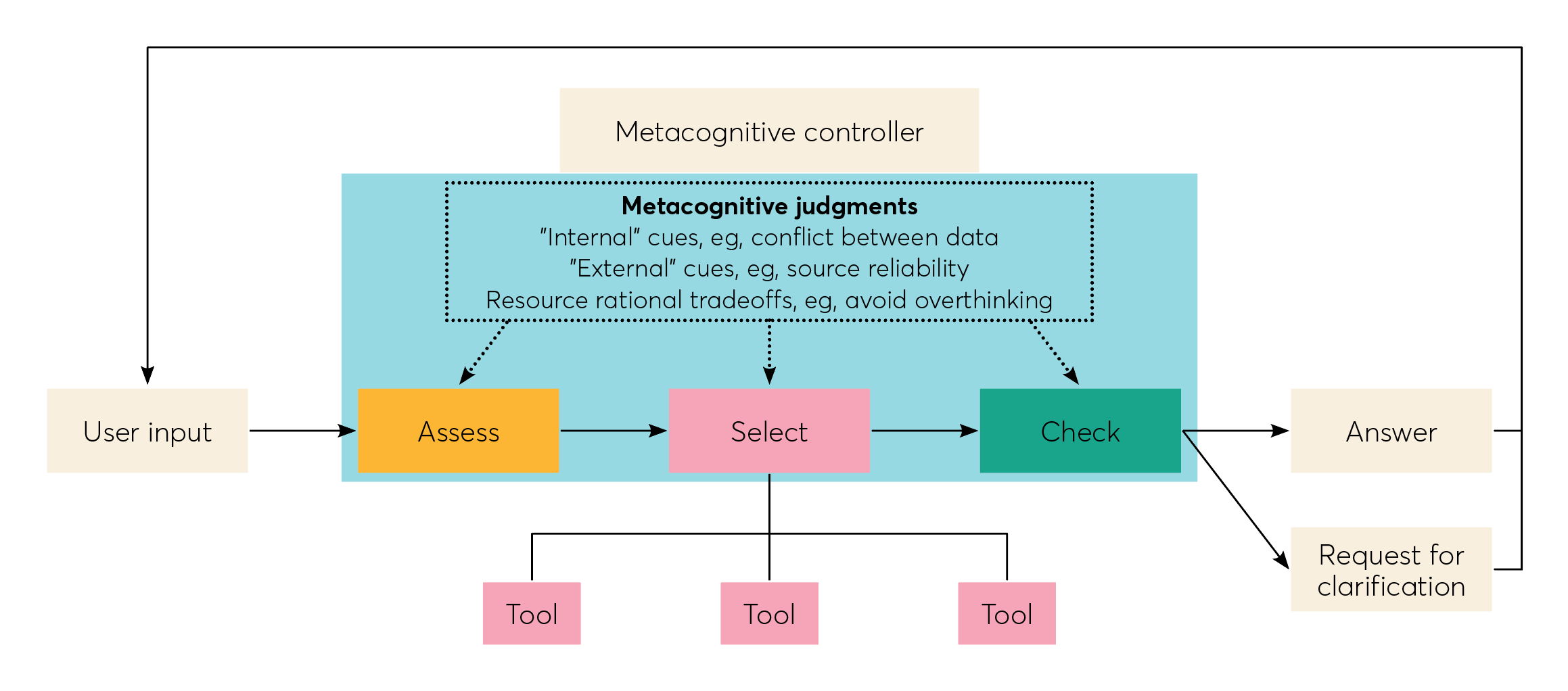
Elisabeth: Yes, the concept is based on the idea of dual-process theory that was popularized by Danny Kahneman and Amos Tversky. Their innovation was that we have two modes of thinking, one that is fast and intuitive, but also prone to error and bias, and one that is slower, more deliberative, but also more effortful, and therefore engaged less but less error-prone. What we’ve seen in recent work on dual-process theory is that it’s not really a binary of systems; it’s a spectrum. The advantage of human intelligence is that we can move between those two systems, to match our cognitive strategy to the problem at hand. Neurosymbolic AI is about bringing together those two ways of reasoning—one which is about fast-thinking pattern recognition, and one that is about slower, more critical, reasoning, and having those two systems work together. A “metacognitive controller” mimics human intelligence by trying to match which mode is used based on the complexity and consequence of the request, and the decision at hand.
Tom: You also speak of “resource rationality” and “meta-reinforcement learning.” Could you explain those?
Elisabeth: So, resource rationality. You might say, “Wouldn’t you just build an AI that’s always in System Two, putting as much computational power at every request as possible to get the best possible outcome?” But people don’t spend all of their time in System Two. The way we use these two systems is enormously efficient because it allows us to process enormous amounts of information and complexity without being overwhelmed. Resource rationality is about having a model that can similarly be efficient in how often it engages, both in terms of time spent and in the compute used.
Michael: And the idea of meta-reinforcement learning is that the LLM would be rewarded for thinking about its own thinking, expressing uncertainty or flagging its own potential errors. That’s instead of just being rewarded for producing a confident-sounding, but wrong, answer. That’s valuable because it trains the AI how to learn to solve problems, rather than just training it on one specific problem. Behavioural scientists can provide a guide here. We might suggest rewards for exploration strategies that humans use to avoid errors, like perspective-seeking.
THE GOOD, THE BAD, AND THE LIKELY
Tom: To conclude, I have three questions for each of you. First, what concerns you about the future of AI and human behaviour? Second, what gives you hope? Third, what seems most likely?
Elisabeth: I’m concerned about the ways that our interactions with AI may reshape human relationships, particularly intimate relationships. AI companions are on the rise and currently largely unregulated, which presents risks particularly for younger people. There’s a risk that the increased use of AI companions could distort the norms and expectations of human relationships, or even substitute them in a way that could actually increase loneliness. There are positive ways that AI companions could be used, for instance as practice grounds for human relationships. But I think it’s important that regulators consider the risks and implement safeguards now.
Deelan: What concerns me most is misinformation: hypertargeted, hyperpersonalized misinformation using AI.
Michael: What concerns me most is cognitive atrophy—the possibility that AI could accelerate a decline in attention focus and critical skills. But that’s not inevitable.
Tom: And your hopes for AI and human behaviour?
Elisabeth: From an organizational perspective, a lot of the discourse about AI adoption is about efficiency, and about how to do the same with fewer resources. I think there’s also a potential discourse about how organisations can raise their ambitions and achieve more with the same resources. That feels like the hopeful future of an organization with talent: that it can achieve an enormous amount more than without AI.
Deelan: Something that gives me hope is democratized learning. In education, there’s a lot of inequality of access to AI, and concern about cognitive atrophy. But LLMs could speed up leveled access to education in various countries. Another thing is the possibility of AI as a deliberative partner and moderator of discussions, and as a way to reduce conspiracy beliefs.
Michael: I’m hopeful that we can use behavioural science to help build AI that is genuinely wiser and more capable. In line with the “Augment” part of the report, I think we can help AI to develop its metacognition—its ability to think about thinking.
Tom: You’ve each cited worries and hopes. Now, what do you consider most likely?
Michael: I think it’s likely that there’s backlash and disillusionment around the abilities of generative AI in the short term, followed by a more realistic sense of how it can add value. In other words, we’ll move further through the hype cycle. Neither the greatest optimists nor the greatest pessimists will be proved right.
Deelan: I think the most likely path is that we are going to continue to see shallow use of AI tools by people, particularly in the workplace. Behaviourally, that reflects three core barriers inhibiting deeper adoption: motivation, capability and trust. Many people don’t yet see a clear personal benefit from using AI, lack the skills or confidence to use it well, or fear how AI might impact their identity. Until organisations address these barriers, thoughtful adoption of AI, where tools genuinely augment rather than replace human skills, will remain the exception.
Elisabeth: We’ve talked about there being a narrow window to shape the evolution of AI, and I worry that we as a society, and as policymakers and regulators, will spend too long admiring the problem and the risks, and not get quickly enough to how we actually shape this. Lots of research collaborations can and should be set up to give us a much better understanding of human-AI interaction. There is a lot of energy in this space, but I would encourage people to run at it even faster.
Very cool ideas! Calcification of AI interaction patterns and designs is an underdiscussed point imo, I love the keyboard example.