



I just heard a maven of the AI scene using a new verb for the addictive practice of testing all you read online in an AI-writing detector. “I’m Pangramming everything lately,” he said, referring to the popular app.
If nobody can tell who (or what) wrote the words, a centuries-long conversation among humanity degenerates. Slop sloshes through debates. Honest authors lose out, and readers wonder what a byline means. Until recently, that seemed our fate. But has AI-detection technology hit a turning point?
To find out, I caught up with the CEO of Pangram, Max Spero, a former Google software engineer who co-founded his company with an ex-roommate from Stanford. When they set out in 2023, the average citizen was still asking, “What IS a large language model?” Max had a different question: “What is society, if we can’t tell human from machine?”
—Tom Rachman, AI Policy Perspectives
[Interview condensed and edited for clarity]
Tom: Here’s a provocative question: Why care about human writing? Perhaps the important part of writing is communicating information. Why not use AI to do that better?
Max: There is a social contract between the writer and the reader. If I believe there is an idea worth sharing, I pay a cost by writing a piece of text, and the reader pays a cost by taking the time to read it. In a future where AI content lets you bypass the cost of writing your idea and formulating it, we get into a situation with perverse incentives, where people are posting total slop, and the reader is taking more time to read than the writer put into the text in the first place.
Tom: I’m not convinced that’s the whole answer. I can imagine cases where it would take an hour to write a letter yourself, but two hours to prompt it with AI. If effort was the key, we’d value the AI-written letter more. I think we care about human writing for reasons beyond effort. First, if the AI author isn’t disclosed, there’s an element of deceit, and we’re offended by lying. Second, even if the person is completely transparent about AI use, we may still mind.
Max: Agreed. The reader-writer relationship is ultimately a relationship between people. Another thing to think about is what can happen with AI writing at scale. It’s so easy to run deceptive operations. They used to have Russian troll farms with hundreds of people writing internet comments. They’ve replaced these with AI and LLMs, and they’re able to run at a much larger scale and push political agendas. On a micro scale you might say, “Well, if I’m looking for a news article, what do I care if it’s AI-generated?” But on a macro scale, understanding the provenance really matters. Otherwise you enable these bad actors to push their agenda.
HOW AI DETECTORS WORK
Tom: When chatbots really took off in early 2023, one of the first parts of society to feel it was education. Students were using them to do assignments, and some educators abandoned the homework essay altogether because they had no way of reliably identifying AI-generated submissions. Can you explain why early attempts at AI detectors failed? Maybe start by explaining the term “perplexity.”
Max: Early AI-detection tools tried to solve the problem by measuring perplexity, which is a metric of how unexpected a piece of text is. Something like, “For lunch, he ate a bowl of soup” is low in perplexity while “For lunch, he ate a bowl of spiders” is high in perplexity. Large language models work by composing probable text, making the writing much less varied, more steady, and therefore low in perplexity. But when humans write, we tend to scatter unexpected things in there, meaning our texts are much more varied, with many parts predictable, other parts slightly less so, and occasional bits that really surprise you. That variation is known as “burstiness,” as if you have spikes of surprise bursting through. AI writing is very low in burstiness. Early on, researchers saw you could use perplexity and burstiness to distinguish human from AI text pretty well, with between 95 percent and 99 percent accuracy.
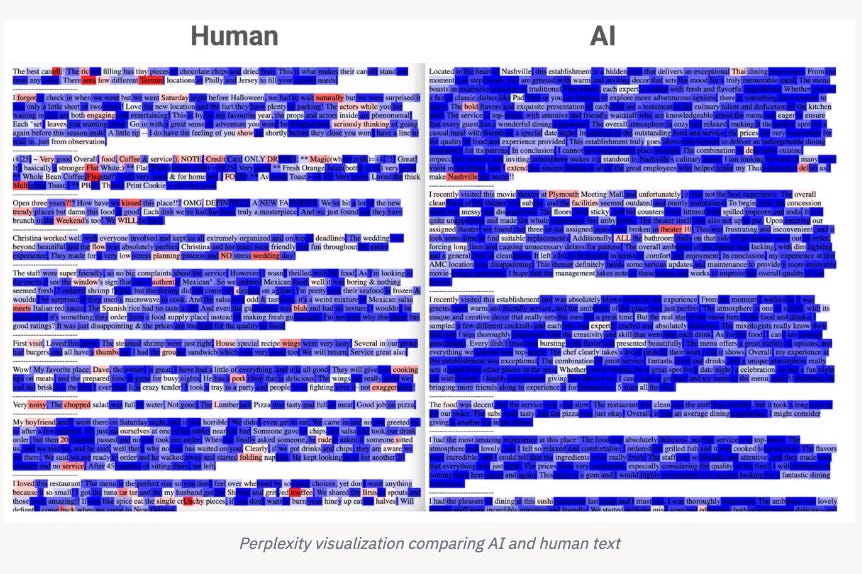
Tom: But you rejected that approach. Why?
Max: First, that level of accuracy might sound good, but it’s still way too many errors to use in the real world. Also, the approach had several problems besides that. One is that any text that happened to appear in the LLM’s training set would seem like probable phrasing to the model, and therefore low perplexity—so something familiar to it, like the Declaration of Independence, might get flagged as AI-generated. Another problem is that people learning English tend to write more simply, meaning their output is low perplexity, and can also get flagged as AI. So, we just threw all of this research out the window, and decided to train a deep-learning classifier.
Tom: This is how I think you built your deep-learning classifier—tell me if I get it right. First, you took an open-weight base model. You fine-tuned it with hundreds of thousands of labeled examples of human text and AI-generated text in various genres. From this, the model learned to differentiate human writing from AI-generated, but imperfectly. So you added a stage of “hard negative mining,” where you took all of the cases where your model had wrongly classified a piece of human writing as artificial—false positives—and you generated AI versions of that same kind of text. You added those examples to the original fine-tuning dataset, then went back to stage one, training the open-weight model from scratch, but now including the edge cases. An algorithm ran this process as a two-stage loop, making it better and better, until you had a product.
Max: What you’re describing was our process when we started Pangram. But we’ve never stopped training models. Keep in mind that we could tune models to be more sensitive to AI content, or we could tune them to be more conservative, and have fewer false positives. Avoiding an incorrect judgment that a piece of human writing was AI-generated is something we’re most careful about avoiding. So we calibrate the model to a rate of 1 in 10,000 false positives, keeping that constant while trying to improve how much AI content we catch, or the model’s “recall.” We’re always running new experiments, bringing in new datasets, new domains of writing. The goal of training new models is not to just slide this tradeoff scale; it’s to move the entire curve. And everything is improving. We’ve also come up with additional important techniques. The main one is training the model to differentiate between full AI generation and AI edits. What we did is ask LLMs to edit text, make it better, fix grammar mistakes, summarize it. Then we measure the distance between the original text and the edited text, and we train our model with that, showing it that a certain distance from human text is equal to a light edit, and further is equal to a moderate edit. We train it to recognize that, in addition to the fully AI-generated text.
Tom: So you have a dashboard, where people can drop in text, and a browser extension that’ll do live checks on social media feeds like LinkedIn and Substack and X. Obviously, your products aren’t much use if they’re flinging out tons of false negatives, letting AI-generated content through the net. But it’s the false positives that’s worse here because a wrongful accusation could be devastating. You might have it down to an average of 1 in 10,000 false positives—but at scale, that still means mistakes. Have you been monitoring false positives in the wild?
Max: Definitely; we have a tracker. If anybody comes to me, and says, “It’s a false positive!”, we’ll triage it internally. Also, on the app dashboard, we have thumbs-up/thumbs-down on the results, so we can track responses at a higher volume. But that is pretty unreliable because often it’s just somebody unhappy that their obvious AI text got flagged.
MYSTERY OVER WHAT THE MODEL SEES
Tom: I want to dwell on the false positive rate for a moment because this concern—wrongful accusations—feels key to adoption of this technology. When you talk about 1 in 10,000 false positives, or 99.99% correct classification, that’s an average across many forms of writing. But the errors are higher for certain types of material, such as recipes, poetry, and how-to articles. Why?
Max: These are all fairly formulaic types of writing, so it’s going to be lower signal. With poetry, it’s also very short texts in most cases.
Tom: And your detector refuses to evaluate anything below 50 words. But when it can give its verdict on a document, is it evaluating the likeliness of AI at the level of each word? Or the paragraphs? Or the entirety of the text?
Max: It’s looking at windows of about 200 to 500 tokens [roughly 150 to 375 words]. We have a system that does a pass, and tries to find rough boundaries between AI and human text, and then we do a finer sweep to try to find more exact boundaries, specifically for mixed text.
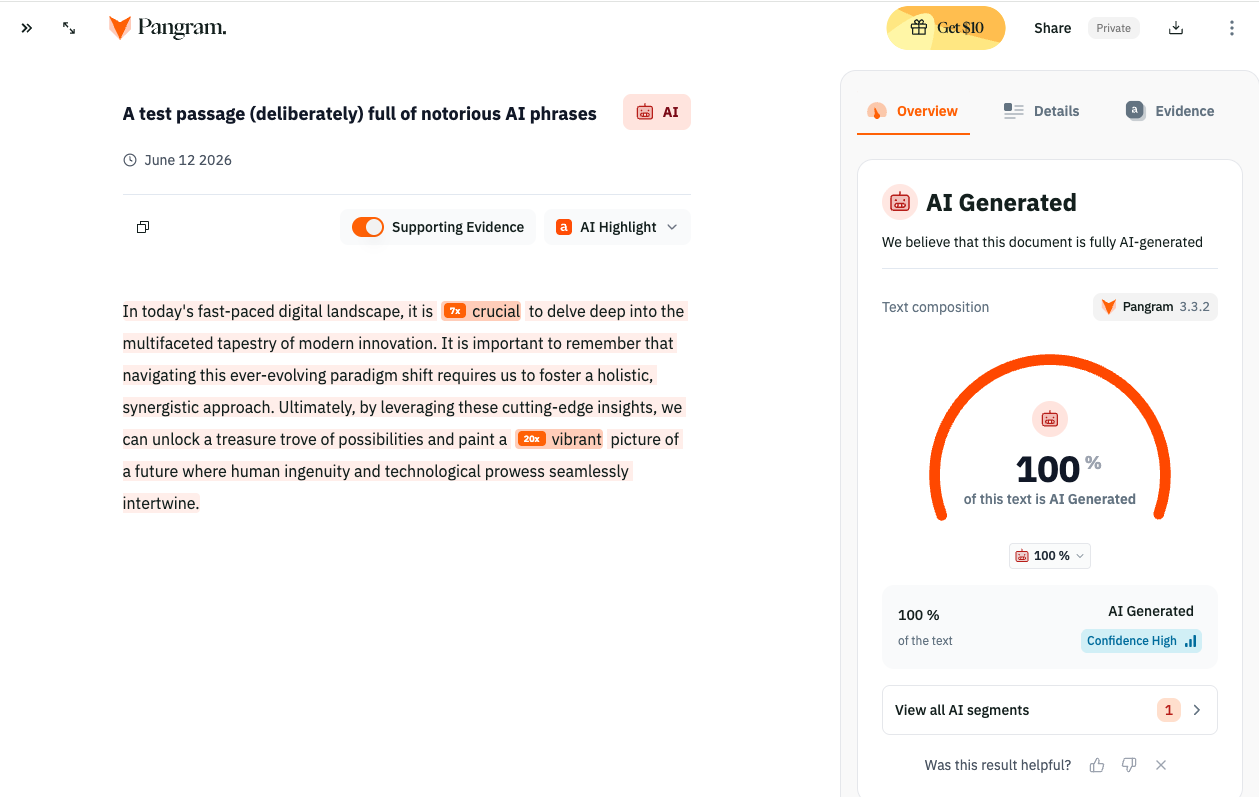
Tom: When it flags a piece of writing, your interface lets the user see “supporting evidence” that something was AI-generated or AI-assisted. That can include the telltale phrasing that people have come to associate with AI writing. But this supporting evidence isn’t actually how your system made its judgment, right? It’s a post-hoc analysis of the text that your model already flagged. Is that because deep-learning is great at somehow identifying AI, but you don’t know precisely what it’s picking up?
Max: Yes, the deep-learning classifier is a black box. We don’t have a ton of interpretability into why it makes the predictions that it does. We include the supporting evidence because there’s always demand from people wondering what makes a text read as AI, and how they can train their own eyes to detect it. But the Pangram classifier is not looking only at the surface-level features. It’s finding patterns in longer-context features that an LLM will use in structuring and writing a doc.
Tom: It’s aware of something exclusively human in writing that we ourselves cannot necessarily put our finger on.
Max: If you’re looking for an objective measure, it might be that LLMs are better than humans in so many ways: they don’t make grammar mistakes, they often have coherent arguments, while if you look at the full distribution of human text, many humans are writing less coherent arguments. But it’s also that LLMs are a lot less diverse: if you ask them to write 100 arguments on a topic, they’re going to cluster in one area, whereas the space of human arguments is going to be very diverse. That’s something AI can’t replicate or reproduce.
Tom: But AI developers will improve the quality of writing. Why think you can keep ahead of that?
Max: To make a frontier model more capable, you have to instill preferences—it has to prefer to do one thing rather than something worse. But it’s these preferences that Pangram is detecting in writing. The most undetectable language models were GPT-2 and GPT-3, where they were not trained to have clear preferences, but to approximate the human distribution of writing. But today’s LLMs have stronger preferences, and this is a big reason we’re able to detect the text so easily. A caveat is that LLMs are getting more complex, so that is a headwind we must deal with. Also, the way people use AI has been changing. It went from a student saying, “Write me an essay” to somebody using an agentic harness, and saying, “Research and write a Substack article on the Strait of Hormuz.” Those are completely different use cases.
AI DETECTION IN THE WILD
Tom: Who is using your models right now, and why?
Max: We have a range of people using them. Universities use this to help with academic integrity. We also have academic conferences such as NeurIPS, the biggest AI conference, which recently said they need position papers to be substantially human-written, and they used Pangram to flag papers that look fully AI-generated, and either desk-reject or give authors a chance to appeal. We also work with some traditional publishers, as well as anybody with datasets who’s worried about the quality. That is an underrated aspect of this: if you’re buying data, you don’t want it to just be slop; you want it to be quality from real experts.
Tom: Which sectors aren’t dealing adequately with AI detection?
Max: Publishing has been really slow to catch up on this. There were a couple of major scandals, like the book Shy Girl that people called out as being AI-generated. It got pulled from shelves. A lot of publishers don’t have a strong AI policy. Some have decided that, as long as the text is good, we’re going to evaluate it on its merits rather than whether it’s AI-generated or not.
Tom: My sense is that most publishers would mind if a piece of writing is AI-generated. If anything, I’d guess that there could be a lag with many in publishing unaware that detection technology now works well. I suspect there’s also an aversion to technological involvement here—that you should trust authors protesting their innocence and not trust an app. I sympathize with that. Anyone accused deserves a fair chance to defend themselves. But failing to take this technology seriously is even more harmful to human authors who actually write their own stories.
Max: They lose something real and tangible.
Tom: What are cases where you’d consider it fine to use AI to write?
Max: I don’t really consider it “using AI to write.” You can publish AI content, and that’s fine, as long as it’s properly disclosed. But if I’m writing an email to somebody, it’s somewhere between impersonal and disrespectful to use AI to write that. AI is a useful tool: we should be using it to generate text, synthesize text, and it’s even reasonable to share AI output. But if we’re talking about “using AI to write,” I’d caution against that framing.
THE FUTURE OF “WRITING”
Tom: We’ve been talking about this as a binary: either human-generated or AI-generated. But maybe we’re destined for a future of cognitive blending with AI, where people outsource parts of thinking, much as we now outsource parts of our memory to machines. Maybe the idea of a human-or-machine binary is a short-lived prospect.
Max: Yes, I could see that, especially with so many applications pushing AI assistance on users. But I think there would still be degrees of human input that would differentiate such writing from the entirely AI-generated.
Tom: So there is a long-term future for human writing?
Max: Definitely. People just care about it. To me, it doesn’t matter how good the AI gets. There’s still a lot of people who care, and a lot of industries, and types of writing, where it really matters that something’s human.
Tom: What would those be for you?
Max: Fiction is one. But also, think of an essay contest. Is the goal really to find the best essay? Or is it to reward writers who have taken the time to write something compelling?
Tom: Well, I think it’s probably both. If it’s an essay contest in a school, say, you’re rewarding effort in part, but you’re also rewarding quality. Or else you’d just give the prize to the kids who tried hardest, and not the ones who wrote well.
Max: Yeah, but if the goal was purely to find the best essay, then maybe we should have LLMs generate 100 completely.
Tom: Unless there’s something in the best writing that requires a human author.